零基础学 Python3 使用 Selenium 获取某大型电商网站商品信息
在当前数字化时代,电商网站已成为人们日常购物的主要平台。对于开发者和数据分析师来说,获取电商网站的商品信息具有重要的应用价值,例如价格监控、竞品分析和市场研究。许多电商网站采用动态加载技术,直接使用传统方法(如 requests 库)可能难以获取完整数据。这时,Selenium 作为一个强大的自动化测试工具,成为解决这一问题的理想选择。本文将从零基础出发,指导您如何使用 Python3 和 Selenium 获取某大型电商网站的商品信息,包括环境搭建、基本操作、数据提取以及常见问题处理。
一、环境准备与安装
要开始使用 Selenium,首先需要安装必要的库和驱动。请确保您已安装 Python3(推荐 3.6 及以上版本),然后通过 pip 安装 Selenium 库:`bash
pip install selenium`
您需要下载与浏览器匹配的 WebDriver,例如 ChromeDriver(适用于 Chrome 浏览器)或 GeckoDriver(适用于 Firefox)。请从官方网站下载并确保其路径添加到系统环境变量中,或直接在代码中指定路径。
二、基础 Selenium 操作
Selenium 允许模拟用户行为,如打开网页、点击按钮和填写表单。以下是一个简单的示例,展示如何启动浏览器并访问一个电商网站:`python
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
启动 Chrome 浏览器(假设 ChromeDriver 在系统路径中)
driver = webdriver.Chrome()
打开电商网站首页(此处以示例网站为例,实际使用时请替换为目标网站)
driver.get('https://www.example-mall.com')
等待页面加载
time.sleep(3)
关闭浏览器
driver.quit()`
在运行代码前,请确保目标网站允许爬虫行为,并遵守 robots.txt 协议和相关法律法规。
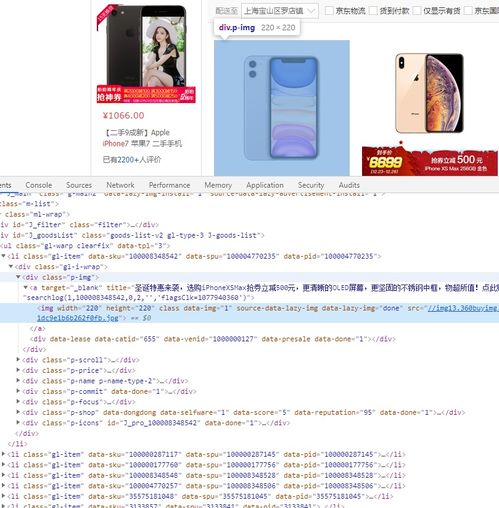
三、定位和提取商品信息
电商网站的商品信息通常包括名称、价格、评论数和描述等。Selenium 提供了多种元素定位方法,如通过 ID、类名、XPath 或 CSS 选择器。以下示例演示如何搜索商品并提取信息:`python
# 假设我们已在目标网站,现在搜索关键词“智能手机”
searchbox = driver.findelement(By.ID, 'search-input') # 根据实际元素 ID 调整
searchbox.sendkeys('智能手机')
search_box.submit()
time.sleep(5) # 等待搜索结果加载
提取商品列表中的第一个商品名称和价格
productname = driver.findelement(By.CLASSNAME, 'product-name').text
productprice = driver.findelement(By.CLASSNAME, 'product-price').text
print(f'商品名称: {productname}')
print(f'价格: {productprice}')`
对于动态加载的内容(如滚动加载更多商品),您可能需要使用显式等待(WebDriverWait)来确保元素出现:`python
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
等待商品元素加载,最多等待 10 秒
wait = WebDriverWait(driver, 10)
productelement = wait.until(EC.presenceofelementlocated((By.CLASS_NAME, 'product-item')))`
通过循环遍历多个元素,您可以批量获取商品信息,并将其存储到列表或文件中(如 CSV 或 JSON)。
四、常见问题与优化建议
1. 反爬虫机制:许多电商网站设有反爬虫措施,如验证码、IP 限制或动态令牌。应对方法包括使用代理 IP、添加延时或使用 Selenium 的隐式等待。请始终尊重网站规则,避免频繁请求。
2. 性能优化:Selenium 可能较慢,因为它模拟真实浏览器。考虑使用 headless 模式(无界面)以提高效率:`python
options = webdriver.ChromeOptions()
options.add_argument('--headless')
driver = webdriver.Chrome(options=options)`
3. 数据存储:将提取的信息保存到文件,便于后续分析。例如,使用 pandas 库导出为 CSV:`python
import pandas as pd
data = {'名称': [productname], '价格': [productprice]}
df = pd.DataFrame(data)
df.tocsv('productinfo.csv', index=False)`
五、总结
通过本文,您学习了如何使用 Python3 和 Selenium 从零开始获取电商网站的商品信息。Selenium 的强大之处在于它能处理 JavaScript 渲染的页面,但使用时需注意合法性和效率。建议在实际项目中结合其他库(如 BeautifulSoup 用于解析静态内容)以优化性能。不断练习和探索,您将能更熟练地应用这些技能于网络数据采集任务中。如果您是初学者,可以从简单网站开始,逐步挑战更复杂的场景。
如若转载,请注明出处:http://www.xc888888.com/product/708.html
更新时间:2026-02-02 03:30:32